技術イベント・カンファレンス運営のノウハウ(1枚目) Advent Calendar 2025 の4日目!
今日は、カンファレンスのコアスタッフとして参加する人に覚えておいてほしいことについて書いていく。と思ったら2日目のこうのさんと方向性だだ被り。1意見として捉えてもらえれば。
これまで関わってきたカンファレンス
自分がカンファレンスに関わったのは2018年に開催されたJapan Container Daysというイベントだ。このイベントはクラウドに関連する勉強会のコラボ的な要素が強く、当時主催していたPaaS勉強会の立場でスタッフとして参加した。その後Japan Container DaysはCloudNative Daysという名前に変わり、2019年の開催からCo-Chair就任を打診され、青山さんと共に5年ほど務めることになった。
CloudNative DaysのCo-Chairを後進に引き継いだのち、Platform Engineering Kaigi(PEK)のChairやObservability Conference TokyoのOrganizer、SRE Kaigiのスタッフなどを務めている。イベント運営経験は割と多いほうだと思う。
カンファレンスのコアスタッフは何をやるのか
カンファレンスのコアスタッフは何をやるのか 。イベントによって詳細は異なるが、典型的なものとしては
- スポンサーとのやり取り
- コンテンツ企画
- プロポーザルの採択
- 会場設計
- 広報活動
- 懇親会の企画
などが挙げられる。
正直に言うと、結構泥臭い仕事が多い。 基本的にはひたすらコミュニケーション、Slackやメールでのやり取り、ミーティング、ドキュメントの作成だ。
運営のタスクをこなしているとふと思うことがある。「あれ、これって仕事と変わらなくね?」
そう、仕事と変わらないようなことをボランティアでやる、それがカンファレンスのスタッフなのである。
それでもスタッフはいいぞ
いきなりネガティブっぽく見えることを書いてしまい、スタッフになって欲しいのか欲しくないのか分からない感じになってしまった。
上に書いた内容は間違いなく事実なのだけど、それでもスタッフはいいぞとお勧めする理由もちゃんとある。
コミュニケーションの本質
まず「仕事と変わらないじゃん」という点。チャットやミーティングでコミュニケーションが発生するのは、仕事がどうこうというよりは、複数人が協力して何か物事を達成しようとしたときに、必ず発生する営みという本質的な話なのだ。だから、カンファレンス運営だろうが町内会だろうがPTAだろうが、必ずコミュニケーションは必要になる。
なので「人とのコミュニケーション絶対無理です・・・!」という人には向いていないと思われるが、「面倒だけど必要とあらば・・・」くらいの人であれば問題ないんじゃないかと思う。コミュニケーションを減らして同じ物事を達成できるならそれに超したことはないので、技術的知識を活かしてコミュニケーションコスト削減する取り組みをやっても良いだろう。
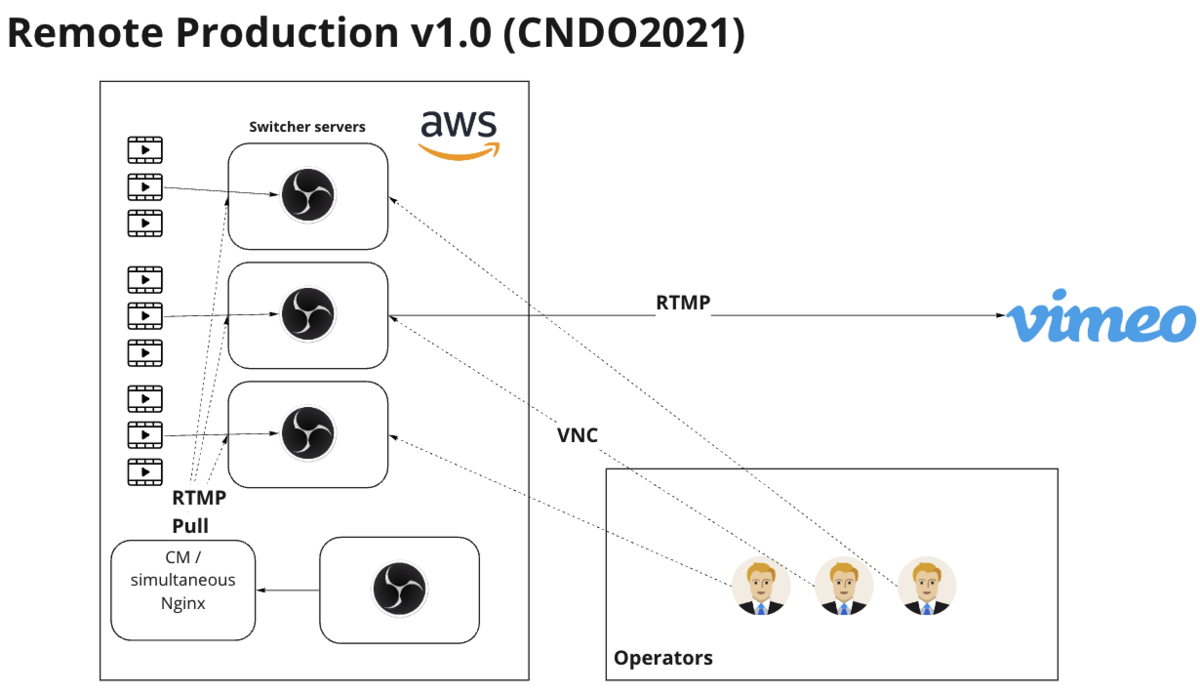
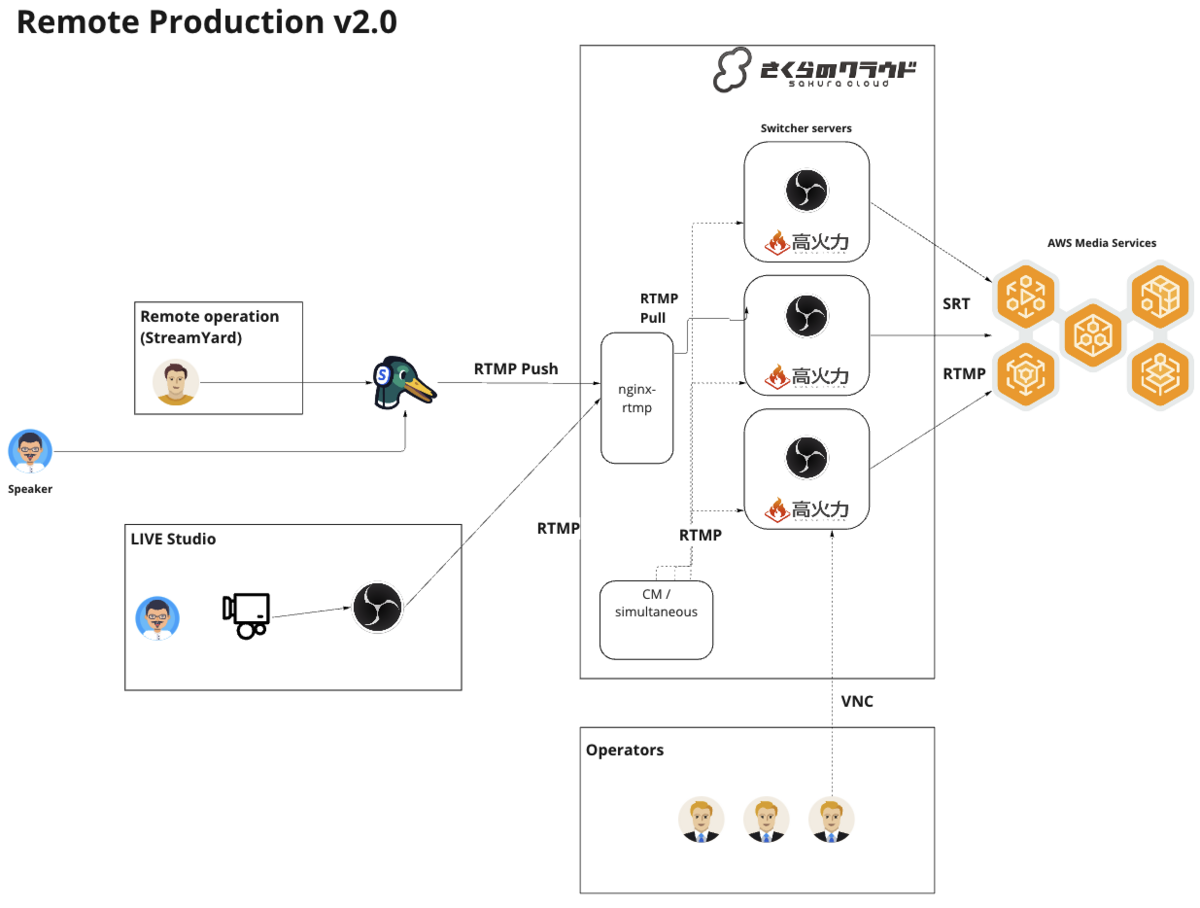
 ▲ PEKではWeekly PEKというドキュメントを毎週自動的に生成して、ミーティングを開かなくても他の人の活動が一目で分かるような工夫をしている
▲ PEKではWeekly PEKというドキュメントを毎週自動的に生成して、ミーティングを開かなくても他の人の活動が一目で分かるような工夫をしている
界隈のすごい人と行動できる
技術カンファレンスには、その界隈で名の知れている人が代表なりスタッフなり登壇者なりで関わっていることが多い。あなたがもし駆け出しのエンジニアであれば、そういう人と接点を持つ機会は少ないだろう。でも、カンファレンスのスタッフになると、そういう人たちと同じ場所で、同じ目的に向かって活動することができる。そうすることで、表に出ている情報だけではない、さまざまな面について学べるだろう。
「この人、情報発信ではそこまで目立ってないけど内部での活動すごいな、組織運営のプロかよ」
みたいな人もいれば
「あ、この人技術面ではすごいけど事務処理面では割とふつうな人だな、親近感」
みたいなこともあるし
「技術力もすごいし情報発信もすごいし組織運営までこなすのかよ、超人か?」
みたいな人もいる。自分の会社以外の人がどのような仕事スタイルなのかを垣間見ることができて、とても学べるものが多い。
コミュニケーションという経験を積める
ふたつ前にも書いたが、社会で活動することの本質はコミュニケーションにある。
適切なタイミングで適切な内容を人に伝えるだとか、会議の場で情報を整理するだとか。「仕事ができるな」と感じる人はこのあたりがとても上手い。
じゃあどうやればそれが上達するかというと、1にも2にも場数である。ビジネス書を読むとあれこれテクニックが解説されているが、所詮テクニックに過ぎない。ひたすら実践しないと上達しない。
自分はファシリテーションやホワイトボーディングを得意としており、本業でもそのスキルを活用しているのだが、どこでそれを培ったか思い起こすと、やっぱりカンファレンススタッフの経験だなと思う。やってなかったらこのスキル付いていなかったように思うし、キャリアも今とは違ったものになっていただろうなと感じる。
決断をするという経験を積める
若手社員のうちは、組織としての意思決定を行う立場になく、何か決断をするという経験を積めないことが多い。大企業ならなおさらだ。
また、外部の業者に見積を取ったりだとか、発注したりだとかの仕事に携わることも少ないかもしれない。
だが、カンファレンススタッフだとそれをやる機会がたくさんある。個人としてもチームとしてもたくさんの決断をしなくてはいけないし、お金を直接扱うようなタスクもある。
企業としてやるよりは規模も額も小さいが、早いうちから経験を積んでおくことで、将来にすごく活きたりするのだ。小さなチームでの決断をしたことがない人が、いきなり大きな仕事の決断なんて出来るわけがない。残念ながら大企業の中間管理職にはそういう人が多かったりするが、カンファレンススタッフで経験を積んでおけばそういった事態を防げる。
なによりも、その決断でクビになったりしないし減給になったりもしない。そもそも支払われてないし。 なので、ドーンと取り組めば良いのだ。
推しの技術の本質に向き合える
イベントの成功とは何か。さまざまな評価軸があるが、最も重要なのは「イベントの価値を多くの人に届けられたか」だ。より平たく言うと「どれだけの人をイベントに呼べたか」。
人に来て貰うには、人にそのイベントが魅力的であると感じてもらわなくてはいけない。だが人によって魅力に思うポイントは異なるので
- 自分たちの推している技術にはどういう価値があり
- どういう人たちをターゲットとしており
- どうやってそこに魅力を届けるか
を考え抜いて、企画やプロモーションに反映していく必要がある。この思考の過程が大変に尊いのだ。
その過程で新たな価値を見つけられるかもしれないし、本業にも生かせるかもしれない。時間を費やすだけの価値がここにはあると思う。
カンファレンス運営の難しさと気をつけるポイント
ここまでスタッフをやるべき理由を書いてきたが、同時に運営の難しさもある。
本業とプライベートは最優先にすべき
スタッフはほぼ全員が本業を別に持っているだろう。さらには家族などのプライベートもある。スタッフとして重要なのは、本業とプライベートは最優先にすべきということだ。経験積めて本業にも役立つ!と説明したが、こちらの活動を優先するがあまり本業が犠牲になっては元も子もない。
本業やプライベートが忙しいときは、遠慮無くそちらを優先すべきだし、全員が同じ認識をもつべきだ。
報酬体系の設計
基本的にカンファレンススタッフはボランティアだ。予算に余裕のあるイベントであれば、謝礼としてAmazonギフト券を配るみたいなことはあるかもしれないが、時給換算するととんでもない金額になるので、金銭的なメリットとしてはほぼゼロと考えた方がいいだろう。
一般企業であれば、給料がそのまま報酬だ。なので、指揮命令系統を構築し、上から下に命令していくことができる。結果が良ければ報酬に反映するし、逆に良くなくても報酬でコントロールすればいい。
だがボランティアで構成されている組織ではそれが難しい。じゃあ何が報酬になるというと、「達成感」や「やりがい」といったものになる。
そのため、2日目のこうのさんの記事にもあるように、仕事を命令して行わせるということはできず、お願いベースにせざるを得ない。これは全てのカンファレンス運営が悩んでいるポイントだと思う。 リンク先にあるPHPカンファレンス名古屋の記事も、わかりみしか無かった。
自分からタスクを拾っていく意識を持つ
このようにヒエラルキーを作りづらい事情があるので、スタッフとして貢献するのであれば自分からタスクを拾っていく意識を持つことが本当に重要だ。こうのさんの記事も書いてあるが、自分からタスクを拾ってくれる人は本当に有り難い存在だ。本業とプライベートに支障がない範囲で、いろんなことをやっていくのがいいだろう。
何らしかのリアクションをする
ちょっと忙しくてタスク拾うのが難しい。でも何らしかの方法で貢献する方法はないか。・・・ある。
それは、「リアクションをする」ということだ。

何か意見を求める投稿があったときや、何かを達成した書き込みがあったとき。それに対して、リアクションを必ずつけてあげる。
これだけでも、人は本当に救われるのだ。
動けないときは必ず言う。黙って居なくならない
前述したように本業とプライベートが最優先。動けないときは仕方ない。
ただ、気をつけるべきなのは「動けなくなったらその場で言う」ということだ。タスクを抱えている場合は特にそれを徹底すべき。忙しくなってタスクこなせなくなることに文句を言う人は誰も居ない。言ってくれれば他の人に振り直すだけなので特に問題はない。
また、初スタッフで気張ってたくさんタスクを抱えてしまい首が回らなくなってしまうこともあるだろう。でも大丈夫、その場で言ってくれればみんな手分けして手伝えるので遠慮無く言って欲しい。
でも、忙しさを理由にタスクを抱えたまま音信不通になってしまうと、本当の本当の本当に困る。状況が分からないので引継ぎも難しいし、継続意思があるのか分からないのでタスクを奪って良いのかどうかも判断に困る。心理的負担も増える。
これだけは絶対にアカンというやつなので、気をつけてほしい。逆にこれ以外の失敗なら、まぁどうとでもなるかな。
まとめ
ということで、カンファレンスのスタッフは大変である一方、得られるものも多いしやりがいもある。
最低限気をつけるべき点さえ抑えておけばいろんな形で貢献ができるので、是非チャレンジしてみてほしい。