先に謝っておくと、タイトルは半分釣り。嘘はついていないのだけど。
ということでEKSをオンプレ環境で動かせるEKS Anywhere (以下EKS-A)がGAに。
aws.amazon.com
現時点で対応している構築環境は、ローカルのDocker上で動かすか、あるいはvSphere環境の2択。"ちゃんとした"環境で動かすとなると、vSphereが第一の選択肢と言うことになりそう。
EKS-Aのドキュメントを見ると、Create production clusterの項目でvSphereに構築する方法が解説されている。今回のタイトルはつまりそういうことで、EKS-AをvSphereにデプロイしてみましたよ、というお話。
EKS-Aの準備をする
EKS-Aでは、環境の構築にCluster APIが使われている。VMwareのTanzu Kubernetes GridもCluster APIなので、vSphere環境でk8sを構築するのであればCluster API、というのが一般的になりそう。
Cluster APIはこのマスコットキャラクターがめちゃくちゃ上手く仕組みを表現していて、Kubernetes Clusterの中にインストールされたCluster APIが、さらにクラウドプロバイダーにアクセスして別のKubernetesを立ち上げるという、親亀子亀のような仕組みになっている。

なので、まずは作業環境にDockerを立ち上げ、その中に eksctl anywhere コマンドでbootstrapのクラスタを立ち上げられるようにする。
EKS-Aのドキュメントでは、この作業環境のことを Administrative machine と呼んでおり、現時点ではMac OSか、Ubuntuを公式ではサポートしている。他のディストリビューションでもいけるのではと思うが、試していないので分からないし、無駄なトラブルを避けるためにもまずは推奨環境で行うのが良いだろう。今回はWindowsのWSL2でセットアップしてあるUbuntu 20.04 + Docker Desktopという構成でやってみた。WSL2+Docker Desktopの時点で公式サポートの環境じゃなくなっている気もするが、少なくとも自分の環境では動いた。
Dockerのインストール方法は割愛。
以下のコマンドで最新の eksctl をインストール。バージョン0.66.0が入るはずだ。
curl "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" \
--silent --location \
| tar xz -C /tmp
sudo mv /tmp/eksctl /usr/local/bin/
次に eksctl-anywhere pluginをセットアップ。
export EKSA_RELEASE="0.5.0" OS="$(uname -s | tr A-Z a-z)"
curl "https://anywhere-assets.eks.amazonaws.com/releases/eks-a/1/artifacts/eks-a/v${EKSA_RELEASE}/${OS}/eksctl-anywhere-v${EKSA_RELEASE}-${OS}-amd64.tar.gz" \
--silent --location \
| tar xz ./eksctl-anywhere
sudo mv ./eksctl-anywhere /usr/local/bin/
AWSのトリさんが教えてくれたところによると、このプラグイン機構はeksctl 0.66.0から導入されたということなので、もし上手く動かない場合はeksctlのバージョンを確認してみると良い。
vSphere側の準備をする
次にvSphere側の準備をする。 Productionというだけあって、リソースはガッツリ必要になる。 デフォルトだと7VM立ち上がるのだが、それぞれに2 vCPU, 8GB RAM, 20GB Diskが必要だ。つまり14 vCPU, 56GB RAM。 オーバーコミットをしたとしても、まぁそれなりに覚悟は必要なリソース量にはなるだろう。 自分はたまたまガッツリ試せる環境を自宅に組んでいたので問題なかったのだが。
また、vSphereのバージョンはvSphere7.0以上が必須。自分は最新の7.0U1cを利用した。
利用するネットワークにはDHCPが必須。この制約はTKGと一緒なのだが、割と引っかかりやすいポイントなので要注意。
まず、vCenterからResource poolを作成。今回はEKSAという名前にしてみた。
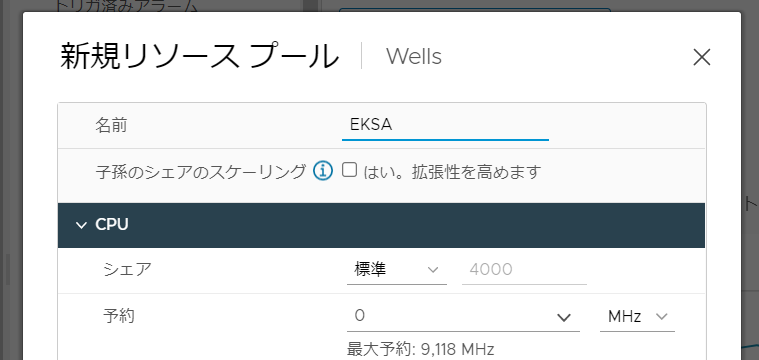
次にフォルダを作成。新規仮想マシンおよびテンプレートフォルダを選択し、 EKSAという名前で作成。
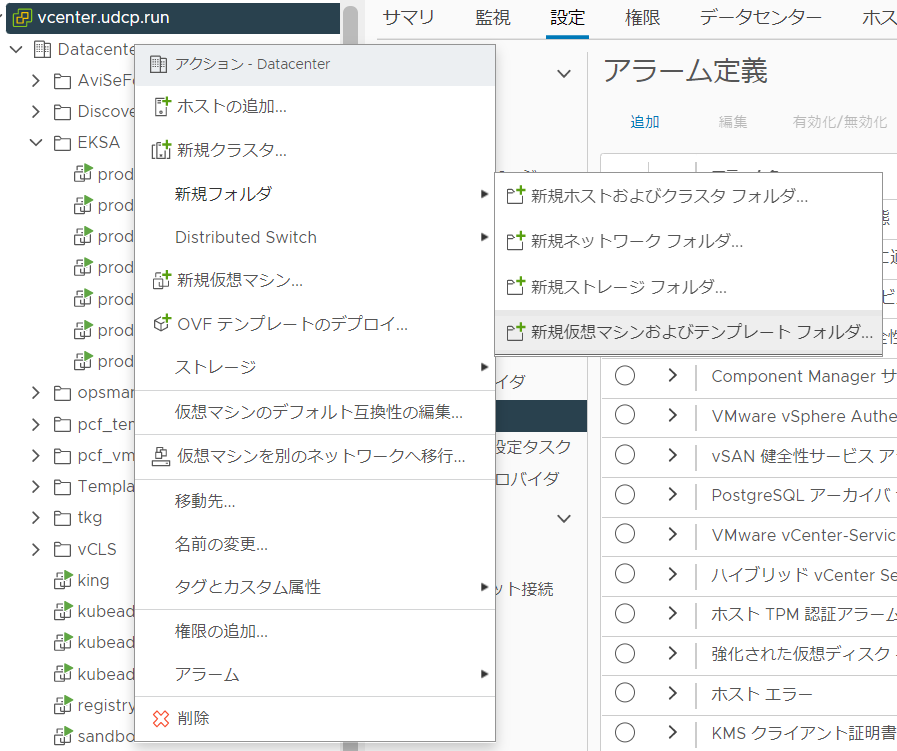
また、これはドキュメントに無くてハマりポイントだが、Templates という名前のフォルダも併せて作っておく。これを作らないとエラーでコケてしまった。
Cluster configを作る
以下のコマンドでコンフィグファイルを生成
CLUSTER_NAME=prod
eksctl anywhere generate clusterconfig $CLUSTER_NAME \
--provider vsphere > eksa-cluster.yaml
生成したコンフィグファイルを開いてみると、KubernetesのYAMLになっており、Cluster APIによるリソースが定義されていることが分かる。
次にこのファイルの必要事項を修正する。
まずClusterリソースのendpointを修正。これが作成されるKubrenetesのAPIエンドポイントになる。
controlPlaneConfiguration:
count: 2
endpoint:
host: "10.9.8.190" #これ
machineGroupRef:
同じリソースで externalEtcdConfiguration workerNodeGroupConfigurations controlPlaneConfiguration が設定可能になっていて、count の値を変更することでVMの台数を変えることが出来る。必要に応じて変更しよう。
次に、VSphereDatacenterConfigを修正。
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: VSphereDatacenterConfig
metadata:
name: prod
spec:
datacenter: "Datacenter" #必須
insecure: true #任意
network: "VM Network" #必須
server: "vcenter.udcp.run" #必須
thumbprint: "" #任意
datacenter にはvSphere上のDatacenter、 networkにはVMをぶら下げたいネットワーク、 serverにはvCenterのアドレスを入れておく。vCenterが自己署名証明書の場合は insecureを true にするか、 thumbprintを設定する。
次に、 3つあるVSphereMachineConfigを修正。 prod-cpがk8sのcontrol plane、prod-etcdがetcd、prodがworker nodeのリソースになっている。それぞれ別の値を設定可能だが、今回は全て同じ設定を施すことにする。
以下のコメントが付いている部分を、環境に合わせて変更する
spec:
datastore: "vsanDatastore" # 利用したいデータストア
diskGiB: 25
folder: "EKSA" # さっき作成した仮想マシンのフォルダ
memoryMiB: 8192
numCPUs: 2
osFamily: bottlerocket # 利用したいOSを指定。今回はbottlerocket
resourcePool: "EKSA" #さっき作成したリソースプール
users:
- name: ec2-user #bottlerocket の場合はec2-userを指定
sshAuthorizedKeys:
- "ssh-rsa AAAAB3NzaC1yc...j" #作成されたVMにログインできるようにするための公開鍵を入れておく
デプロイする!
vCenterにアクセスするための認証情報を環境変数に入れておく。
export EKSA_VSPHERE_USERNAME='administrator@vsphere.local'
export EKSA_VSPHERE_PASSWORD='t0p$ecret'
そして以下のコマンドで構築開始。
eksctl anywhere create cluster -f eksa-cluster.yaml -v 9
ドキュメントには無かったが、 -v オプションでログレベルを変更できるとトリさんが教えてくれた。ありがたや。初期構築の場合何かとコンフィグの設定ミスを起こしやすいのだが、デフォルトのログレベルだと進捗がほとんど表示されないのでエラーが起きていても気づきにくい。 -vで高めの数字をしておくことで、トラブル時にも状況を把握しやすくなる。
最終的に以下のような表示がされれば構築完了。

作られたものを見ていく。
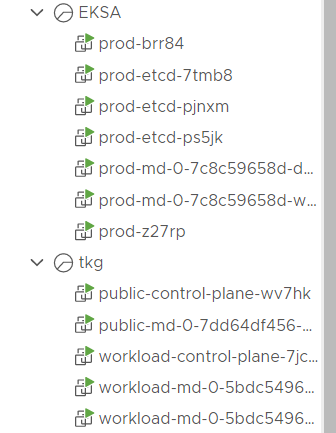
リソースグループを見てみると、7台のVMが構築されていることが分かる。ちなみに画像の下のリソースグループはVMware Tanzu Kubernetes Gridで構築した環境だ。同じCluster APIを利用しているため、VMの命名ルールが似ていることが分かるだろう。
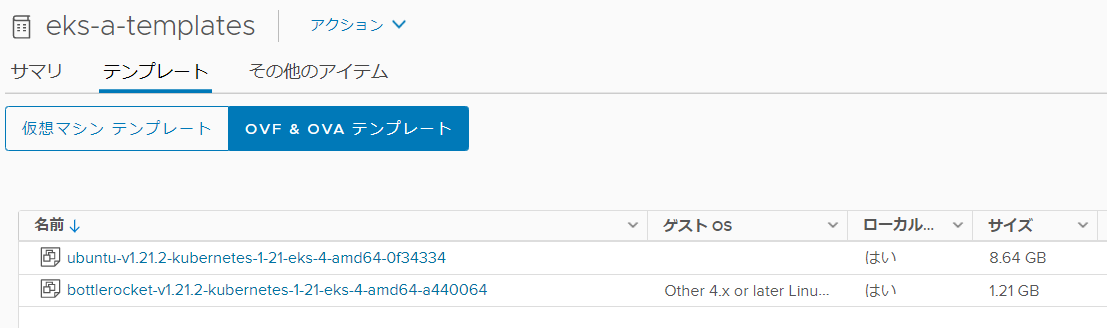
コンテンツライブラリを見てみると、eks-a-templates という名前のライブラリが作成されており、その中にOVAテンプレートが追加されている。現バージョンではbottlerocketとubuntuが選択可能なのだが、ubuntuイメージは8.64GBと巨大のため、VMの起動が非常に遅かった・・・。Tanzu Kubernetes Gridの場合はubuntuでも1.5GB程度なので、何故こんなにサイズが大きいのかは謎。
作成されたk8sにアクセスするには、kubeconfigファイルが生成されているのでそれを指定
export KUBECONFIG=${PWD}/${CLUSTER_NAME}/${CLUSTER_NAME}-eks-a-cluster.kubeconfig
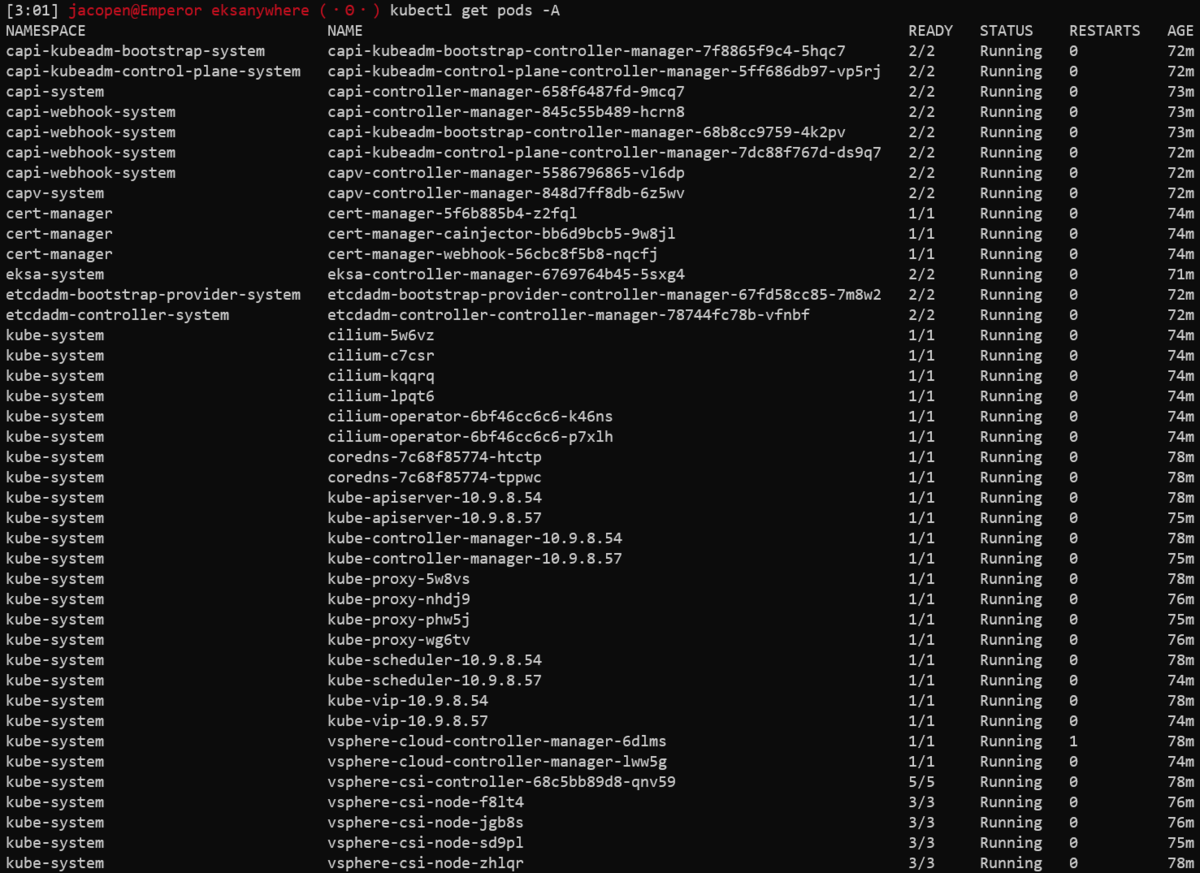
叩いてみると色々動いていることがわかる。
kubeconfigを毎回指定するのが面倒なので、必要であれば ~/.kube/config に内容をマージしたほうがいいかもしれない。
CNIにはCiliumが利用されている。CSIは標準でvSphere CSIが設定されているため、そのままPVが作成可能だ。
kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
standard (default) csi.vsphere.vmware.com Delete Immediate false 76m
LoadBalancerは、ドキュメントだとKube-vipの利用がRecommendedになっている。(個人的にあまりいい印象がないのだけど・・・)
ちなみに既にControl planeにはkube-vipがデプロイされており、Kubernetes APIの公開に利用されている。
その他FluxによるGitOpsがサポートされているなどいくつか特徴があるので、皆さんお試しあれ(これはDockerで構築しても使えるはず)
ハマったこと
オンプレならではというか、環境の差異によるハマりポイントがあったので以下メモ
public.ecr.awsからaccess denied食らって死んだ
パブリックの方のECRを以前使っていたんだけど、そのログイン情報が切れていたのかいきなりこれを食らった。get-login-passwordをやり直して解消。
eksctl anywhere create cluster -f eksa-cluster.yaml
Error: failed to create cluster: unable to initialize executables: failed to setup eks-a dependencies: Error response from daemon: pull access denied for public.ecr.aws/eks-anywhere/cli-tools, repository does not exist or may require 'docker login': denied: Your authorization token has expired. Reauthenticate and try again.
コンテンツライブラリで死んだ
若干分かりづらいエラーだったが、コンテンツライブラリへの転送でエラーと出た。原因としては、vCenterのDNS設定が間違っており名前が引けない状態だったため、OVAファイルをインターネットから持ってこれずこのエラーになった様子。この状態になってしまうと、DNS設定を直してもコンテンツライブラリにゴミが残っており、そのゴミを手動で消してあげる必要があった。
Creating template. This might take a while.
❌ Validation failed {"validation": "vsphere Provider setup is valid", "error": "failed importing template into library: error importing template: govc: The import of library item d7869312-b889-4400-b489-af20cf1e177f has failed. Reason: Error transferring file bottlerocket-v1.21.2-eks-d-1-21-4-eks-a-1-amd64.ova to ds:///vmfs/volumes/vsan:5208a8224f1b7452-258c9915a44aa6a5//contentlib-b06b09de-5b24-4be6-86a9-b344590a9681/d7869312-b889-4400-b489-af20cf1e177f/bottlerocket-v1.21.2-eks-d-1-21-4-eks-a-1-amd64_c4187670-2a9b-4a5b-86dd-a1e8a0bd0d18.ova?serverId=86f3a054-9ba4-4b8f-81b6-b7070451c5cc. Reason: Error during transfer of ds:///vmfs/volumes/vsan:5208a8224f1b7452-258c9915a44aa6a5//contentlib-b06b09de-5b24-4be6-86a9-b344590a9681/d7869312-b889-4400-b489-af20cf1e177f/bottlerocket-v1.21.2-eks-d-1-21-4-eks-a-1-amd64_c4187670-2a9b-4a5b-86dd-a1e8a0bd0d18.ova?serverId=86f3a054-9ba4-4b8f-81b6-b7070451c5cc: IO error during transfer of ds:/vmfs/volumes/vsan:5208a8224f1b7452-258c9915a44aa6a5/contentlib-b06b09de-5b24-4be6-86a9-b344590a9681/d7869312-b889-4400-b489-af20cf1e177f/bottlerocket-vmware-k8s-1.21-x86_64-1.2.0-ccf1b754_c4187670-2a9b-4a5b-86dd-a1e8a0bd0d18.vmdk: Pipe closed.\n", "remediation": ""}
Error: failed to create cluster: validations failed
Templateの作成で死んだ
これは本文中にも書いた通り。ドキュメントの記載漏れなんじゃないかなー? Template用のフォルダを作っておく必要がある。
❌ Validation failed {"validation": "vsphere Provider setup is valid", "error": "failed deploying template: error deploying template: govc: folder '/Datacenter/vm/Templates' not found\n", "remediation": ""}
Error: failed to create cluster: validations failed
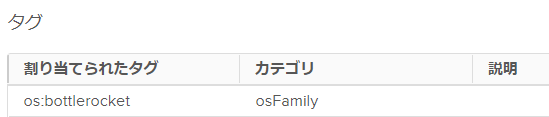
タグが適切に設定されなくて死んだ
これ、諸々試行錯誤してたら突然出なくなって解消して、結局原因は謎。 テンプレートに必要なタグが設定されておらず死ぬパターン。 この問題を引いてしまった場合は、手動でTemplateファイルのタグにosFamilyの設定を入れてあげる必要があった。
❌ Validation failed {"validation": "vsphere Provider setup is valid", "error": "failed tagging template: govc returned error when attaching tag to /Datacenter/vm/Templates/bottlerocket-v1.21.2-kubernetes-1-21-eks-4-amd64-a440064: govc: 400 Bad Request: {\"type\":\"com.vmware.vapi.std.errors.invalid_argument\",\"value\":{\"error_type\":\"INVALID_ARGUMENT\",\"messages\":[{\"args\":[\"urn:vmomi:InventoryServiceTag:28bd7acf-262b-4c48-a53a-775ed91b34e1:GLOBAL\",\"DynamicID (com.vmware.vapi.std.dynamic_ID) => {\\n type = VirtualMachine,\\n id = vm-1554590:86f3a054-9ba4-4b8f-81b6-b7070451c5cc\\n}\"],\"default_message\":\"Tagging associable types violation\",\"id\":\"\"}]}}\n", "remediation": ""}
Error: failed to create cluster: validations failed
etcd以外のノードが上がらずに死んだ
これ、結局原因が分からず、何もしてないのに直った・・・(マジ)
bottlerocketでこの問題を引き、その後ubuntuにしたら普通に立ち上がった。 で、その後bottlerocketに戻したら何故かちゃんと立ち上がった・・・。